Strava: Guide to data extraction and analysis§

A picture of the Strava Mobile Application
Strava is often regarded as the “social network for athletes.” It lets you track your running and riding with GPS, join Challenges, share photos from your activities, and follow friends.
Strava follows a fremium model offering a digital service accessible through its mobile applications (iOS and Android). Users also have an option to upgrade and unlock more advanced features like Custom Goals, Training Plans, Race Analysis, etc for a monthly fee of $5-8.
We’ve been using the strava application for the past few weeks and we will show you how to extract its data, visualize your runs and compute correlations between multiple metrics of the data. The Strava API allows the users to extract all sorts of data on athletes, segments, routes, clubs, and gear. However, for this notebook we will be focusing on metrics of the participant’s activities like dates, speed, elevation, duration, etc.
We will be able to extract the following parameters:
Parameter Name |
Sampling Frequency |
|---|---|
Moving Time |
Per Activity |
Elapsed Time |
Per Activity |
Average Speed |
Per Activity |
Maximum Speed |
Per Activity |
Average Cadence |
Per Activity |
Maximum Cadence |
Per Activity |
Average Watts |
Per Activity |
Maximum Watts |
Per Activity |
Average Heart Rate |
Per Activity |
Maximum Heartrate |
Per Activity |
Distance |
Records every change in user’s position |
Polyline Summary |
Records every change in user’s position |
Total Elevation Gain |
Sampling Frequency depends upon user’s fitness tracker |
Heart Rate |
Sampling Frequency depends upon user’s fitness tracker |
Heart Rate (Stream Data) |
Sampling Frequency depends upon user’s fitness tracker (usually per second) |
In this guide, we sequentially cover the following five topics to extract data from Cronometer servers:
Set up
Authentication/Authorization
Requires only client_id, client_secret and refresh_token.
Data extraction
We get data via wearipedia in a couple lines of code
Data Exporting
We export all of this data to file formats compatible by R, Excel, and MatLab.
Adherence
We simulate non-adherence by dynamically removing datapoints from our simulated data.
Visualization
We create a simple plot to visualize our data.
Advanced visualization
7.1 Visualizing participant’s Overall Activity!
7.2 Visualizing participant’s Weekly Summary!
7.3 Visualizing Participant’s Runs!
Data Analysis
8.1 Analyzing correlation between Participant’s data!
Outlier Detection
9.1 Highlighting Outliers!
Disclaimer: this notebook is purely for educational purposes. All of the data currently stored in this notebook is purely synthetic, meaning randomly generated according to rules we created. Despite this, the end-to-end data extraction pipeline has been tested on our own data, meaning that if you enter your own email and password on your own Colab instance, you can visualize your own real data. That being said, we were unable to thoroughly test the timezone functionality, though, since we only have one account, so beware.
1. Setup§
Participant Setup§
Dear Participant,
Once you download the strava app, please set it up by following these resources: - Written guide: https://www.runnersworld.com/beginner/g25619156/what-is-strava/ - Video guide: https://www.youtube.com/watch?v=LHtCxdrZFJ8&ab_channel=RunWithJ
Make sure that your phone is logged to the strava app using the Strava login credentials (email and password) given to you by the data receiver.
Best,
Wearipedia
Data Receiver Setup§
Please follow the below steps:
Create an email address for the participant, for example
foo@email.com.Create a Strava account with the email
foo@email.comand some random password.Keep
foo@email.comand password stored somewhere safe.Distribute the device to the participant and instruct them to follow the participant setup letter above.
Next, go to https://developers.strava.com/
Click on “Create and Manage your App”

Strava will prompt you to login. Make sure to login with the account that participants’ credentials
Fill out your details: Here’s an example with some dummy information!

Next, Strava will ask you to upload a app icon. I personally uploaded the Strava logo in the option.
 Copy and crop the Image to your preference and hit save!
Copy and crop the Image to your preference and hit save! 
You’re done!
 Copy and paste your your client ID, Client Token and Refresh token in the box below and give it to the researcher.
Copy and paste your your client ID, Client Token and Refresh token in the box below and give it to the researcher.Install the
wearipediaPython package to easily extract data from this device via the Strava API.
[1]:
!pip install wearipedia
!pip install openpyxl
Requirement already satisfied: wearipedia in /Users/saarth/opt/anaconda3/lib/python3.9/site-packages (0.1.0)
Requirement already satisfied: scipy<2.0,>=1.6 in /Users/saarth/opt/anaconda3/lib/python3.9/site-packages (from wearipedia) (1.9.3)
Requirement already satisfied: garminconnect<0.2.0,>=0.1.48 in /Users/saarth/opt/anaconda3/lib/python3.9/site-packages (from wearipedia) (0.1.49)
Requirement already satisfied: beautifulsoup4<5.0.0,>=4.11.1 in /Users/saarth/opt/anaconda3/lib/python3.9/site-packages (from wearipedia) (4.11.1)
Requirement already satisfied: polyline<2.0.0,>=1.4.0 in /Users/saarth/opt/anaconda3/lib/python3.9/site-packages (from wearipedia) (1.4.0)
Requirement already satisfied: rich<13.0.0,>=12.6.0 in /Users/saarth/opt/anaconda3/lib/python3.9/site-packages (from wearipedia) (12.6.0)
Requirement already satisfied: typer[all]<0.7.0,>=0.6.1 in /Users/saarth/opt/anaconda3/lib/python3.9/site-packages (from wearipedia) (0.6.1)
Requirement already satisfied: myfitnesspal<3.0.0,>=2.0.1 in /Users/saarth/opt/anaconda3/lib/python3.9/site-packages (from wearipedia) (2.0.1)
Requirement already satisfied: pandas<2.0,>=1.1 in /Users/saarth/opt/anaconda3/lib/python3.9/site-packages (from wearipedia) (1.5.2)
Requirement already satisfied: tqdm<5.0.0,>=4.64.1 in /Users/saarth/opt/anaconda3/lib/python3.9/site-packages (from wearipedia) (4.64.1)
Requirement already satisfied: wget<4.0,>=3.2 in /Users/saarth/opt/anaconda3/lib/python3.9/site-packages (from wearipedia) (3.2)
Requirement already satisfied: soupsieve>1.2 in /Users/saarth/opt/anaconda3/lib/python3.9/site-packages (from beautifulsoup4<5.0.0,>=4.11.1->wearipedia) (2.3.1)
Requirement already satisfied: cloudscraper in /Users/saarth/opt/anaconda3/lib/python3.9/site-packages (from garminconnect<0.2.0,>=0.1.48->wearipedia) (1.2.66)
Requirement already satisfied: requests in /Users/saarth/opt/anaconda3/lib/python3.9/site-packages (from garminconnect<0.2.0,>=0.1.48->wearipedia) (2.28.2)
Requirement already satisfied: blessed<2.0,>=1.8.5 in /Users/saarth/opt/anaconda3/lib/python3.9/site-packages (from myfitnesspal<3.0.0,>=2.0.1->wearipedia) (1.19.1)
Requirement already satisfied: measurement<4.0,>=3.2.0 in /Users/saarth/opt/anaconda3/lib/python3.9/site-packages (from myfitnesspal<3.0.0,>=2.0.1->wearipedia) (3.2.0)
Requirement already satisfied: python-dateutil<3,>=2.4 in /Users/saarth/opt/anaconda3/lib/python3.9/site-packages (from myfitnesspal<3.0.0,>=2.0.1->wearipedia) (2.8.2)
Requirement already satisfied: browser-cookie3<1,>=0.16.1 in /Users/saarth/opt/anaconda3/lib/python3.9/site-packages (from myfitnesspal<3.0.0,>=2.0.1->wearipedia) (0.16.3)
Requirement already satisfied: lxml<5,>=4.2.5 in /Users/saarth/opt/anaconda3/lib/python3.9/site-packages (from myfitnesspal<3.0.0,>=2.0.1->wearipedia) (4.9.1)
Requirement already satisfied: numpy>=1.20.3 in /Users/saarth/opt/anaconda3/lib/python3.9/site-packages (from pandas<2.0,>=1.1->wearipedia) (1.21.2)
Requirement already satisfied: pytz>=2020.1 in /Users/saarth/opt/anaconda3/lib/python3.9/site-packages (from pandas<2.0,>=1.1->wearipedia) (2022.1)
Requirement already satisfied: six>=1.8.0 in /Users/saarth/opt/anaconda3/lib/python3.9/site-packages (from polyline<2.0.0,>=1.4.0->wearipedia) (1.16.0)
Requirement already satisfied: pygments<3.0.0,>=2.6.0 in /Users/saarth/opt/anaconda3/lib/python3.9/site-packages (from rich<13.0.0,>=12.6.0->wearipedia) (2.11.2)
Requirement already satisfied: commonmark<0.10.0,>=0.9.0 in /Users/saarth/opt/anaconda3/lib/python3.9/site-packages (from rich<13.0.0,>=12.6.0->wearipedia) (0.9.1)
Requirement already satisfied: click<9.0.0,>=7.1.1 in /Users/saarth/opt/anaconda3/lib/python3.9/site-packages (from typer[all]<0.7.0,>=0.6.1->wearipedia) (8.0.4)
Requirement already satisfied: shellingham<2.0.0,>=1.3.0 in /Users/saarth/opt/anaconda3/lib/python3.9/site-packages (from typer[all]<0.7.0,>=0.6.1->wearipedia) (1.5.0)
Requirement already satisfied: colorama<0.5.0,>=0.4.3 in /Users/saarth/opt/anaconda3/lib/python3.9/site-packages (from typer[all]<0.7.0,>=0.6.1->wearipedia) (0.4.5)
Requirement already satisfied: wcwidth>=0.1.4 in /Users/saarth/opt/anaconda3/lib/python3.9/site-packages (from blessed<2.0,>=1.8.5->myfitnesspal<3.0.0,>=2.0.1->wearipedia) (0.2.5)
Requirement already satisfied: keyring in /Users/saarth/opt/anaconda3/lib/python3.9/site-packages (from browser-cookie3<1,>=0.16.1->myfitnesspal<3.0.0,>=2.0.1->wearipedia) (23.13.1)
Requirement already satisfied: SecretStorage in /Users/saarth/opt/anaconda3/lib/python3.9/site-packages (from browser-cookie3<1,>=0.16.1->myfitnesspal<3.0.0,>=2.0.1->wearipedia) (3.3.3)
Requirement already satisfied: lz4 in /Users/saarth/opt/anaconda3/lib/python3.9/site-packages (from browser-cookie3<1,>=0.16.1->myfitnesspal<3.0.0,>=2.0.1->wearipedia) (3.1.3)
Requirement already satisfied: pycryptodomex in /Users/saarth/opt/anaconda3/lib/python3.9/site-packages (from browser-cookie3<1,>=0.16.1->myfitnesspal<3.0.0,>=2.0.1->wearipedia) (3.16.0)
Requirement already satisfied: sympy>=0.7.3 in /Users/saarth/opt/anaconda3/lib/python3.9/site-packages (from measurement<4.0,>=3.2.0->myfitnesspal<3.0.0,>=2.0.1->wearipedia) (1.10.1)
Requirement already satisfied: urllib3<1.27,>=1.21.1 in /Users/saarth/opt/anaconda3/lib/python3.9/site-packages (from requests->garminconnect<0.2.0,>=0.1.48->wearipedia) (1.26.7)
Requirement already satisfied: certifi>=2017.4.17 in /Users/saarth/opt/anaconda3/lib/python3.9/site-packages (from requests->garminconnect<0.2.0,>=0.1.48->wearipedia) (2022.9.24)
Requirement already satisfied: idna<4,>=2.5 in /Users/saarth/opt/anaconda3/lib/python3.9/site-packages (from requests->garminconnect<0.2.0,>=0.1.48->wearipedia) (3.3)
Requirement already satisfied: charset-normalizer<4,>=2 in /Users/saarth/opt/anaconda3/lib/python3.9/site-packages (from requests->garminconnect<0.2.0,>=0.1.48->wearipedia) (2.0.4)
Requirement already satisfied: pyparsing>=2.4.7 in /Users/saarth/opt/anaconda3/lib/python3.9/site-packages (from cloudscraper->garminconnect<0.2.0,>=0.1.48->wearipedia) (3.0.9)
Requirement already satisfied: requests-toolbelt>=0.9.1 in /Users/saarth/opt/anaconda3/lib/python3.9/site-packages (from cloudscraper->garminconnect<0.2.0,>=0.1.48->wearipedia) (0.10.1)
Requirement already satisfied: mpmath>=0.19 in /Users/saarth/opt/anaconda3/lib/python3.9/site-packages (from sympy>=0.7.3->measurement<4.0,>=3.2.0->myfitnesspal<3.0.0,>=2.0.1->wearipedia) (1.2.1)
Requirement already satisfied: jaraco.classes in /Users/saarth/opt/anaconda3/lib/python3.9/site-packages (from keyring->browser-cookie3<1,>=0.16.1->myfitnesspal<3.0.0,>=2.0.1->wearipedia) (3.2.3)
Requirement already satisfied: importlib-metadata>=4.11.4 in /Users/saarth/opt/anaconda3/lib/python3.9/site-packages (from keyring->browser-cookie3<1,>=0.16.1->myfitnesspal<3.0.0,>=2.0.1->wearipedia) (4.13.0)
Requirement already satisfied: cryptography>=2.0 in /Users/saarth/opt/anaconda3/lib/python3.9/site-packages (from SecretStorage->browser-cookie3<1,>=0.16.1->myfitnesspal<3.0.0,>=2.0.1->wearipedia) (37.0.1)
Requirement already satisfied: jeepney>=0.6 in /Users/saarth/opt/anaconda3/lib/python3.9/site-packages (from SecretStorage->browser-cookie3<1,>=0.16.1->myfitnesspal<3.0.0,>=2.0.1->wearipedia) (0.8.0)
Requirement already satisfied: cffi>=1.12 in /Users/saarth/opt/anaconda3/lib/python3.9/site-packages (from cryptography>=2.0->SecretStorage->browser-cookie3<1,>=0.16.1->myfitnesspal<3.0.0,>=2.0.1->wearipedia) (1.15.1)
Requirement already satisfied: zipp>=0.5 in /Users/saarth/opt/anaconda3/lib/python3.9/site-packages (from importlib-metadata>=4.11.4->keyring->browser-cookie3<1,>=0.16.1->myfitnesspal<3.0.0,>=2.0.1->wearipedia) (3.8.0)
Requirement already satisfied: more-itertools in /Users/saarth/opt/anaconda3/lib/python3.9/site-packages (from jaraco.classes->keyring->browser-cookie3<1,>=0.16.1->myfitnesspal<3.0.0,>=2.0.1->wearipedia) (9.0.0)
Requirement already satisfied: pycparser in /Users/saarth/opt/anaconda3/lib/python3.9/site-packages (from cffi>=1.12->cryptography>=2.0->SecretStorage->browser-cookie3<1,>=0.16.1->myfitnesspal<3.0.0,>=2.0.1->wearipedia) (2.21)
Requirement already satisfied: openpyxl in /Users/saarth/opt/anaconda3/lib/python3.9/site-packages (3.0.10)
Requirement already satisfied: et_xmlfile in /Users/saarth/opt/anaconda3/lib/python3.9/site-packages (from openpyxl) (1.1.0)
2. Authentication/Authorization§
To obtain access to data, authorization is required. All you’ll need to do here is just put in your client id, client secret token and refresh token for your Strava account. We’ll use this to extract the data in the sections below.
[2]:
#@title Enter Strava API credentials
client_id = "83434" #@param {type:"string"}
client_secret = "" #@param {type:"string"}
refresh_token = "" #@param {type:"string"}
3. Data Extraction§
Data can be extracted via wearipedia, our open-source Python package that unifies dozens of complex wearable device APIs into one simple, common interface.
First, we’ll set a date range and then extract all of the data within that date range. You can select whether you would like synthetic data or not with the checkbox.
[4]:
#@title Enter start and end dates (in the format yyyy-mm-dd)
#set start and end dates - this will give you all the data from 2000-01-01 (January 1st, 2000) to 2100-02-03 (February 3rd, 2100), for example
start_date='2022-03-01' #@param {type:"string"}
end_date='2022-06-17' #@param {type:"string"}
synthetic = True #@param {type:"boolean"}
[5]:
import wearipedia
device = wearipedia.get_device("strava/strava")
if not synthetic:
device.authenticate({
'client_id':client_id,
'client_secret':client_secret,
'refresh_token':refresh_token
# Add id if you want to get high frequency stream data (heartrate)
# 'id': '123456789'
})
params = {"start_date": start_date, "end_date": end_date}
distance = device.get_data("distance", params=params)
moving_time = device.get_data("moving_time", params=params)
elapsed_time = device.get_data("elapsed_time", params=params)
total_elevation_gain = device.get_data("total_elevation_gain", params=params)
average_speed = device.get_data("average_speed", params=params)
max_speed = device.get_data("max_speed", params=params)
average_heartrate = device.get_data("average_heartrate", params=params)
max_heartrate = device.get_data("max_heartrate", params=params)
map_summary_polyline = device.get_data("map_summary_polyline", params=params)
elev_high = device.get_data("elev_high", params=params)
elev_low = device.get_data("elev_low", params=params)
average_cadence = device.get_data("average_cadence", params=params)
average_watts = device.get_data("average_watts", params=params)
kilojoules = device.get_data("kilojoules", params=params)
# Make sure that the id is present in the params for heartrate stream data when running for non-synthetic data
heartrate = device.get_data("heartrate", params=params)
4. Data Exporting§
In this section, we export all of this data to formats compatible with popular scientific computing software (R, Excel, Google Sheets, Matlab). Specifically, we will first export to JSON, which can be read by R and Matlab. Then, we will export to CSV, which can be consumed by Excel, Google Sheets, and every other popular programming language.
Exporting to JSON (R, Matlab, etc.)§
Exporting to JSON is fairly simple. We export each datatype separately and also export a complete version that includes all simultaneously.
[34]:
import json
def datacleanup(data):
for d in data:
d['start_date'] = str(d['start_date'])
return data
json.dump(datacleanup(distance), open("distance.json", "w"))
json.dump(datacleanup(moving_time), open("moving_time.json", "w"))
json.dump(datacleanup(elapsed_time), open("elapsed_time.json", "w"))
json.dump(datacleanup(total_elevation_gain), open("total_elevation_gain.json", "w"))
json.dump(datacleanup(average_speed), open("average_speed.json", "w"))
json.dump(datacleanup(max_speed), open("max_speed.json", "w"))
json.dump(datacleanup(average_heartrate), open("average_heartrate.json", "w"))
json.dump(datacleanup(max_heartrate), open("max_heartrate.json", "w"))
json.dump(datacleanup(map_summary_polyline), open("map_summary_polyline.json", "w"))
json.dump(datacleanup(elev_high), open("elev_high.json", "w"))
json.dump(datacleanup(elev_low), open("elev_low.json", "w"))
json.dump(datacleanup(average_cadence), open("average_cadence.json", "w"))
json.dump(datacleanup(average_watts), open("average_watts.json", "w"))
json.dump(datacleanup(kilojoules), open("kilojoules.json", "w"))
complete = {
"distance": distance,
'moving_time':moving_time,
'elapsed_time':elapsed_time,
'total_elevation_gain':total_elevation_gain,
'average_speed':average_speed,
'max_speed':max_speed,
'average_heartrate':average_heartrate,
'max_heartrate':max_heartrate,
'map_summary_polyline':map_summary_polyline,
'elev_high':elev_high,
'elev_low':elev_low,
'average_cadence':average_cadence,
'average_watts':average_watts,
'kilojoules':kilojoules
}
json.dump(complete, open("complete.json", "w"))
Feel free to open the file viewer (see left pane) to look at the outputs!
Exporting to CSV and XLSX (Excel, Google Sheets, R, Matlab, etc.)§
Exporting to CSV/XLSX requires a bit more processing, since they enforce a pretty restrictive schema.
We will thus export steps, heart rates, and breath rates all as separate files.
[35]:
import pandas as pd
distance_df = pd.DataFrame.from_dict(complete['distance'])
distance_df.to_csv('distance.csv')
distance_df.to_excel('distance.xlsx')
moving_time_df = pd.DataFrame.from_dict(complete['moving_time'])
moving_time_df.to_csv('moving_time.csv')
moving_time_df.to_excel('moving_time.xlsx')
elapsed_time_df = pd.DataFrame.from_dict(complete['elapsed_time'])
elapsed_time_df.to_csv('elapsed_time.csv')
elapsed_time_df.to_excel('elapsed_time.xlsx')
total_elevation_gain_df = pd.DataFrame.from_dict(complete['total_elevation_gain'])
total_elevation_gain_df.to_csv('total_elevation_gain.csv')
total_elevation_gain_df.to_excel('total_elevation_gain.xlsx')
average_speed_df = pd.DataFrame.from_dict(complete['average_speed'])
average_speed_df.to_csv('average_speed.csv')
average_speed_df.to_excel('average_speed.xlsx')
max_speed_df = pd.DataFrame.from_dict(complete['max_speed'])
max_speed_df.to_csv('max_speed.csv')
max_speed_df.to_excel('max_speed.xlsx')
average_heartrate_df = pd.DataFrame.from_dict(complete['average_heartrate'])
average_heartrate_df.to_csv('average_heartrate.csv')
average_heartrate_df.to_excel('average_heartrate.xlsx')
max_heartrate_df = pd.DataFrame.from_dict(complete['max_heartrate'])
max_heartrate_df.to_csv('max_heartrate.csv')
max_heartrate_df.to_excel('max_heartrate.xlsx')
map_summary_polyline_df = pd.DataFrame.from_dict(complete['map_summary_polyline'])
map_summary_polyline_df.to_csv('map_summary_polyline.csv')
map_summary_polyline_df.to_excel('map_summary_polyline.xlsx')
elev_high_df = pd.DataFrame.from_dict(complete['elev_high'])
elev_high_df.to_csv('elev_high.csv')
elev_high_df.to_excel('elev_high.xlsx')
elev_low_df = pd.DataFrame.from_dict(complete['elev_low'])
elev_low_df.to_csv('elev_low.csv')
elev_low_df.to_excel('elev_low.xlsx')
average_cadence_df = pd.DataFrame.from_dict(complete['average_cadence'])
average_cadence_df.to_csv('average_cadence.csv')
average_cadence_df.to_excel('average_cadence.xlsx')
average_watts_df = pd.DataFrame.from_dict(complete['average_watts'])
average_watts_df.to_csv('average_watts.csv')
average_watts_df.to_excel('average_watts.xlsx')
kilojoules_df = pd.DataFrame.from_dict(complete['kilojoules'])
kilojoules_df.to_csv('kilojoules.csv')
kilojoules_df.to_excel('kilojoules.xlsx')
Again, feel free to look at the output files and download them.
5. Adherence§
The device simulator already automatically randomly deletes small chunks of the day. In this section, we will simulate non-adherence over longer periods of time from the participant (day-level and week-level).
Then, we will detect this non-adherence and give a Pandas DataFrame that concisely describes when the participant has had their device on and off throughout the entirety of the time period, allowing you to calculate how long they’ve had it on/off etc.
We will first delete a certain % of blocks either at the day level or week level, with user input.
[36]:
#@title Non-adherence simulation
block_level = "day" #@param ["day", "week"]
adherence_percent = 0.89 #@param {type:"slider", min:0, max:1, step:0.01}
[37]:
complete = {
"distance": distance,
'moving_time':moving_time,
'elapsed_time':elapsed_time,
'total_elevation_gain':total_elevation_gain,
'average_speed':average_speed,
'max_speed':max_speed,
'average_heartrate':average_heartrate,
'max_heartrate':max_heartrate,
'map_summary_polyline':map_summary_polyline,
'elev_high':elev_high,
'elev_low':elev_low,
'average_cadence':average_cadence,
'average_watts':average_watts,
'kilojoules':kilojoules
}
[38]:
import numpy as np
if block_level == "day":
block_length = 1
elif block_level == "week":
block_length = 7
# This function will randomly remove datapoints from the
# data we have recieved from Cronometer based on the
# adherence_percent
def AdherenceSimulator(data):
num_blocks = len(data) // block_length
num_blocks_to_keep = int(adherence_percent * num_blocks)
idxes = np.random.choice(np.arange(num_blocks), replace=False,
size=num_blocks_to_keep)
adhered_data = []
for i in range(len(data)):
if i in idxes:
start = i * block_length
end = (i + 1) * block_length
for j in range(i,i+1):
adhered_data.append(data[j])
return adhered_data
# Adding adherence for distance
distance = AdherenceSimulator(distance)
# Adding adherence for moving_time
moving_time = AdherenceSimulator(moving_time)
# Adding adherence for elapsed_time
elapsed_time = AdherenceSimulator(elapsed_time)
# Adding adherence for total_elevation_gain
total_elevation_gain = AdherenceSimulator(total_elevation_gain)
# Adding adherence for average_speed
average_speed = AdherenceSimulator(average_speed)
# Adding adherence for max_speed
max_speed = AdherenceSimulator(max_speed)
# Adding adherence for average_heartrate
average_heartrate = AdherenceSimulator(average_heartrate)
# Adding adherence for max_heartrate
max_heartrate = AdherenceSimulator(max_heartrate)
# Adding adherence for map_summary_polyline
map_summary_polyline = AdherenceSimulator(map_summary_polyline)
# Adding adherence for elev_high
elev_high = AdherenceSimulator(elev_high)
# Adding adherence for elev_low
elev_low = AdherenceSimulator(elev_low)
# Adding adherence for average_cadence
average_cadence = AdherenceSimulator(average_cadence)
# Adding adherence for average_watts
average_watts = AdherenceSimulator(average_watts)
# Adding adherence for kilojoules
kilojoules = AdherenceSimulator(kilojoules)
And now we have significantly fewer datapoints! This will give us a more realistic situation, where participants may take off their device for days or weeks at a time.
Now let’s detect non-adherence. We will return a Pandas DataFrame sampled at every day.
[39]:
distance_df = pd.DataFrame.from_dict(distance)
moving_time_df = pd.DataFrame.from_dict(moving_time)
elapsed_time_df = pd.DataFrame.from_dict(elapsed_time)
total_elevation_gain_df = pd.DataFrame.from_dict(total_elevation_gain)
average_speed_df = pd.DataFrame.from_dict(average_speed)
max_speed_df = pd.DataFrame.from_dict(max_speed)
average_heartrate_df = pd.DataFrame.from_dict(average_heartrate)
max_heartrate_df = pd.DataFrame.from_dict(max_heartrate)
map_summary_polyline_df = pd.DataFrame.from_dict(map_summary_polyline)
elev_high_df = pd.DataFrame.from_dict(elev_high)
elev_low_df = pd.DataFrame.from_dict(elev_low)
average_cadence_df = pd.DataFrame.from_dict(average_cadence)
average_watts_df = pd.DataFrame.from_dict(average_watts)
kilojoules_df = pd.DataFrame.from_dict(kilojoules)
We can plot this out, and we get adherence at one-day frequency throughout the entirety of the data collection period. For this chart we will plot Energy consumed over the time period from the dailySummary dataframe.
[40]:
distance_df_daily = distance_df.assign(start_date = distance_df.get('start_date').apply(lambda x: x[:10]))
distance_df_daily = distance_df_daily.groupby('start_date').sum(numeric_only=True)
import matplotlib.pyplot as plt
import datetime
dates = pd.date_range(start_date,end_date)
energy = []
for d in dates:
res = distance_df_daily[distance_df_daily.index == datetime.datetime.strftime(d,
'%Y-%m-%d')]['distance']
if len(res) == 0:
energy.append(None)
else:
energy.append(res.iloc[0])
plt.figure(figsize=(12, 6))
plt.plot(dates, energy)
plt.show()
6. Visualization§
We’ve extracted lots of data, but what does it look like?
In this section, we will be visualizing our three kinds of data in a simple, customizable plot! This plot is intended to provide a starter example for plotting, whereas later examples emphasize deep control and aesthetics.
[41]:
#@title Basic Plot
feature = "average_speed" #@param ['moving_time', 'elapsed_time','total_elevation_gain','average_speed']
start_date = "2022-03-04" #@param {type:"date"}
time_interval = "full time" #@param ["one week", "full time"]
smoothness = 0.02 #@param {type:"slider", min:0, max:1, step:0.01}
smooth_plot = True #@param {type:"boolean"}
import matplotlib.dates as mdates
import matplotlib.pyplot as plt
from datetime import datetime, timedelta
start_date = datetime.strptime(start_date, '%Y-%m-%d')
if time_interval == "one week":
day_idxes = [i for i,d in enumerate(dates) if d >= start_date and d <= start_date + timedelta(days=7)]
end_date = start_date + timedelta(days=7)
elif time_interval == "full time":
day_idxes = [i for i,d in enumerate(dates) if d >= start_date]
end_date = dates[-1]
if feature == "moving_time":
moving_time_daily = moving_time_df.assign(start_date = moving_time_df.get('start_date').apply(lambda x: x[:10]))
moving_time_daily = moving_time_daily.groupby('start_date').sum(numeric_only=True)
concat_moving_time = []
for i,d in enumerate(dates):
day = d.strftime('%Y-%m-%d')
if i in day_idxes:
mt = moving_time_daily[moving_time_daily.index==day]
if len(mt) != 0:
concat_moving_time += [(day,mt.iloc[0].moving_time)]
else:
concat_moving_time += [(day,None)]
ts = [x[0] for x in concat_moving_time]
day_arr = [x[1] for x in concat_moving_time]
sigma = 200 * smoothness
title_fillin = "Moving Time"
if feature == "elapsed_time":
elapsed_time_daily = elapsed_time_df.assign(start_date = elapsed_time_df.get('start_date').apply(lambda x: x[:10]))
elapsed_time_daily = elapsed_time_daily.groupby('start_date').sum(numeric_only=True)
concat_elapsed_time = []
for i,d in enumerate(dates):
day = d.strftime('%Y-%m-%d')
if i in day_idxes:
et = elapsed_time_daily[elapsed_time_daily.index==day]
if len(et) != 0:
concat_elapsed_time += [(day,et.iloc[0].elapsed_time)]
else:
concat_elapsed_time += [(day,None)]
ts = [x[0] for x in concat_elapsed_time]
day_arr = [x[1] for x in concat_elapsed_time]
sigma = 200 * smoothness
title_fillin = "Elpased Time"
if feature == "total_elevation_gain":
total_elevation_gain_daily = total_elevation_gain_df.assign(start_date = total_elevation_gain_df.get('start_date').apply(lambda x: x[:10]))
total_elevation_gain_daily = total_elevation_gain_daily.groupby('start_date').sum(numeric_only=True)
concat_total_elevation_gain = []
for i,d in enumerate(dates):
day = d.strftime('%Y-%m-%d')
if i in day_idxes:
et = total_elevation_gain_daily[total_elevation_gain_daily.index==day]
if len(et) != 0:
concat_total_elevation_gain += [(day,et.iloc[0].total_elevation_gain)]
else:
concat_total_elevation_gain += [(day,None)]
ts = [x[0] for x in concat_total_elevation_gain]
day_arr = [x[1] for x in concat_total_elevation_gain]
sigma = 200 * smoothness
title_fillin = "Total Elevation Gain"
if feature == "average_speed":
average_speed_daily = average_speed_df.assign(start_date = average_speed_df.get('start_date').apply(lambda x: x[:10]))
average_speed_daily = average_speed_daily.groupby('start_date').sum(numeric_only=True)
concat_average_speed = []
for i,d in enumerate(dates):
day = d.strftime('%Y-%m-%d')
if i in day_idxes:
et = average_speed_daily[average_speed_daily.index==day]
if len(et) != 0:
concat_average_speed += [(day,et.iloc[0].average_speed)]
else:
concat_average_speed += [(day,None)]
ts = [x[0] for x in concat_average_speed]
day_arr = [x[1] for x in concat_average_speed]
sigma = 200 * smoothness
title_fillin = "Average Speed"
with plt.style.context('ggplot'):
fig, ax = plt.subplots(figsize=(15, 8))
if smooth_plot:
def to_numpy(day_arr):
arr_nonone = [x for x in day_arr if x is not None]
mean_val = int(np.mean(arr_nonone))
for i,x in enumerate(day_arr):
if x is None:
day_arr[i] = mean_val
return np.array(day_arr)
none_idxes = [i for i,x in enumerate(day_arr) if x is None]
day_arr = to_numpy(day_arr)
from scipy.ndimage import gaussian_filter
day_arr = list(gaussian_filter(day_arr, sigma=sigma))
for i, x in enumerate(day_arr):
if i in none_idxes:
day_arr[i] = None
plt.plot(ts, day_arr)
start_date_str = start_date.strftime('%Y-%m-%d')
end_date_str = end_date.strftime('%Y-%m-%d')
plt.title(f"{title_fillin} from {start_date_str} to {end_date_str}",
fontsize=20)
plt.xlabel("Date")
plt.xticks(ts[::int(len(ts)/8)])
plt.ylabel(title_fillin)
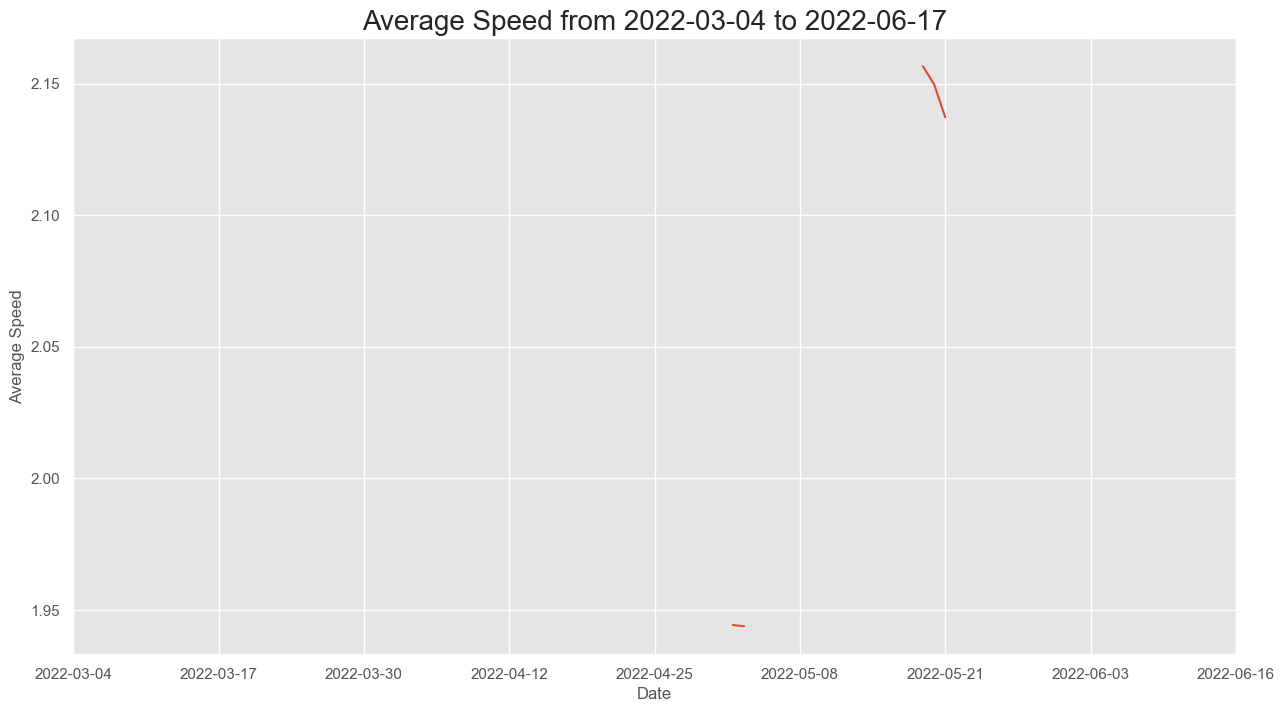
This plot allows you to quickly scan your data at many different time scales (week and full) and for different kinds of measurements (heart rate and weight), which enables easy and fast data exploration.
Furthermore, the smoothness parameter makes it easy to look for patterns in long-term trends.
7. Advanced Visualization§
Now we’ll do some more advanced plotting that at times features hardcore matplotlib hacking with the benefit of aesthetic quality.
7.1 Visualizing participant’s Overall Activity!§
Whenever our participant is curious and logs into Strava to check their overall summary, the Strava app would present their data in the form of a barchart. It should look something similar to this:  Above is a plot from the app!
Above is a plot from the app!
Now that we have user’s data, let’s try to recreate the chart above using our python skills!
[42]:
elevation_df = total_elevation_gain_df.assign(total_elevation_gain
= total_elevation_gain_df['total_elevation_gain'].apply(lambda elevation: elevation*3.281))
elevation_df = elevation_df.merge(distance_df.get(['distance','start_date']),on='start_date')
elevation_df = elevation_df.merge(moving_time_df.get(['moving_time','start_date']),on='start_date')
elevation_df
[42]:
| name | id | start_date | total_elevation_gain | distance | moving_time | |
|---|---|---|---|---|---|---|
| 0 | Morning Run | 7170552790 | 2022-05-19T13:56:56Z | 62.339 | 4584.1 | 1994 |
| 1 | Morning Run | 7154793821 | 2022-05-16T15:40:51Z | 68.901 | 2898.4 | 1252 |
| 2 | Afternoon Run | 7154793774 | 2022-05-16T00:19:48Z | 29.529 | 2747.3 | 1049 |
| 3 | Morning Run | 7154793791 | 2022-05-14T17:31:06Z | 154.207 | 4472.2 | 1822 |
| 4 | Afternoon Ride | 7127406869 | 2022-05-03T14:06:34Z | 0.000 | 0.0 | 6 |
| 5 | Morning Run | 7127406894 | 2022-05-03T13:43:13Z | 0.000 | 1320.5 | 632 |
[43]:
from datetime import datetime, timedelta, date
import seaborn as sns
#@title Set date range for the chart above
start = "2022-04-25" #@param {type:"date"}
end = "2022-05-25" #@param {type:"date"}
#Converting all the elevation gains from metres to feet
elevation_df = total_elevation_gain_df.assign(total_elevation_gain
= total_elevation_gain_df['total_elevation_gain'].apply(lambda elevation: elevation*3.281))
elevation_df = elevation_df.merge(distance_df.get(['distance','start_date']),on='start_date')
elevation_df = elevation_df.merge(moving_time_df.get(['moving_time','start_date']),on='start_date')
#Function that converts data into a date time object
datefixer = lambda date: datetime.fromisoformat(date[0:10])
#Applying datefixer function to every column of elevation_df
elevation_df = elevation_df.assign(date
= elevation_df.get('start_date').apply(datefixer))
#Dictionary to store dates froms start to end date along with elevations
date_etime = {}
#Starting date of our chart
start_date = date(int(start.split('-')[0]),int(start.split('-')[1]),
int(start.split('-')[2]))
#Ending date of our chart
end_date = date(int(end.split('-')[0]),int(end.split('-')[1]),
int(end.split('-')[2]))
#A list of all dates between start and end date
dates = list(pd.date_range(start_date,end_date-timedelta(days=1),freq='d'))
# Storing toal distance, time and elevation
total_distance = 0
total_time = 0
total_elevation = 0
#Loop to find the elevation for each date within the Data Frame
for date_val in dates:
#Initializes the current date in the dictionary as zero
date_etime[str(date_val.day)+" "+str(date_val.month_name())[:3]] = 0
for actvity_index in range(len(elevation_df)):
#Checks if the current date is in the activity DataFrame
if(date_val == elevation_df.iloc[actvity_index].get('date')):
#Storing total time, distance and elevation
total_distance = (total_distance
+ elevation_df.iloc[actvity_index].get('distance'))
total_time = (total_time +
elevation_df.iloc[actvity_index].get('moving_time'))
total_elevation = (total_elevation +
elevation_df.iloc[actvity_index].get('total_elevation_gain'))
#Stores the elevation of current date in dictionary
date_etime[(str(date_val.day)+" "+
str(date_val.month_name())[:3])] = (date_etime[
str(date_val.day)+" "+str(date_val.month_name())[:3]] +
elevation_df.iloc[actvity_index].get('total_elevation_gain'))
#Resetting seaborn to prevent interference with matplotlib plots
sns.reset_orig()
# custom font
# https://stackoverflow.com/questions/35668219/how-to-set-up-a-custom-font-with-custom-path-to-matplotlib-global-font
# download the font and unzip (quiet so it does not print)
!wget -q 'https://dl.dafont.com/dl/?f=mustica_pro'
!unzip -qo "index.html?f=mustica_pro"
# move to directory where fonts should be kept
!mv MusticaPro-SemiBold.otf /usr/share/fonts/truetype/
# build cache, redirect to /dev/null to suppress stdout output
!fc-cache -f -v > /dev/null
import matplotlib as mpl
import matplotlib.font_manager as fm
# try and except, just in case something fails we fallback onto the
# default font
try:
fe = fm.FontEntry(
#font name
fname='/usr/share/fonts/truetype/MusticaPro-SemiBold.otf',
name='mustica-pro')
fm.fontManager.ttflist.insert(0, fe) # or append is fine
mpl.rcParams['font.family'] = fe.name # = 'your custom ttf font name'
except:
pass
#Creating a matplotlib plot of size 16,4
plt1 = plt.figure(figsize=(16,4))
ax = plt1.gca()
#Plotting a bar chart with our data in the dictionary
plt.bar(date_etime.keys(),date_etime.values(),color="#0098DB", width=0.9)
#Adding the title to the chart
plt.title( "$\\bf{"+str(round(total_distance / 1609,1))+"}$mi | "+
"$\\bf{"+str(round(total_time/3600))+"}$h "+"$\\bf{"+
str(round(total_time%60))+"}$m | "
+"$\\bf{"+str(round(total_elevation))+"}$ft")
#Only showing xticks for one day/week
ax.set_xticks(ax.get_xticks()[::7])
#Limiting the y-axis based on our reference chart
plt.ylim((0,350))
plt.ylabel("Total Elevation Gain (Feet)",color="#a1a1a1")
# Removing the spines on top, left and right
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
ax.spines['left'].set_visible(False)
ax.tick_params(left=False, bottom=True)
#Setting the bottom spine to be the same color as the reference chart
ax.spines['bottom'].set_color('#0098DB')
plt.show()
mv: rename MusticaPro-SemiBold.otf to /usr/share/fonts/truetype/: No such file or directory
zsh:1: command not found: fc-cache
findfont: Font family 'mustica-pro' not found.
findfont: Font family 'mustica-pro' not found.

7.2 Visualizing participant’s Weekly Summary!§
If our participant is curious about a more detailed breakdown of their runs, Strava would show you their weekly summary using the following chart:  Again, Let’s try to recreate it using the data we have fetched from the Strava API Note: Weekly summary includes all the runs, walks and rides walks recorded by the participant.
Again, Let’s try to recreate it using the data we have fetched from the Strava API Note: Weekly summary includes all the runs, walks and rides walks recorded by the participant.
Enter the dates for the start and end dates for this chart below!
[44]:
#@title Set date range for the chart above
start = "2022-04-27" #@param {type:"date"}
end = "2022-05-04" #@param {type:"date"}
#Function that converts data into a date time object
datefixer = lambda date: datetime.fromisoformat(date[0:10])
#Applying datefixer function to every column of df_strava_summary
df_strava_summary = elevation_df.assign(date
=elevation_df.get('start_date').apply(datefixer))
#Dictionary to store the hourly frequency
date_etime = {}
#Starting date of our chart
start_date = date(int(start.split('-')[0]),
int(start.split('-')[1]),int(start.split('-')[2]))
#Ending date of our chart
end_date = date(int(end.split('-')[0]),
int(end.split('-')[1]),int(end.split('-')[2]))
#Creating a list of dates between start and end date
dates = list(pd.date_range(start_date,end_date-timedelta(days=1),freq='d'))
# Storing toal distance, time and elevation
total_distance = 0
total_time = 0
total_elevation = 0
for date_val in dates:
date_etime[str(date_val.day)+" "+str(date_val.month_name())[:3]] = 0
for actvity_index in range(len(df_strava_summary)):
#Checks if the current date is in the activity DataFrame
if(date_val == df_strava_summary.iloc[actvity_index].get('date')):
#Storing total time, distance and elevation
total_distance = (total_distance +
df_strava_summary.iloc[actvity_index].get('distance'))
total_time = (total_time +
df_strava_summary.iloc[actvity_index].get('moving_time'))
total_elevation = (total_elevation +
df_strava_summary.iloc[actvity_index].get('total_elevation_gain'))
#Stores the elevation of moving time in dictionary
date_etime[str(date_val.day)+" "
+str(date_val.month_name())[:3]] = (date_etime[str(date_val.day)
+" "+str(date_val.month_name())[:3]] +
df_strava_summary.iloc[actvity_index].get('moving_time')/60)
#Resetting seaborn to prevent interference with matplotlib plots
sns.reset_orig()
# Creating a matplotlib plot of size 16,8
plt1 = plt.figure(figsize=(16,8))
ax = plt1.gca()
plt.plot(list(date_etime.keys()),list(date_etime.values()),color="#FC5200",
marker='o', fillstyle='none', lw=3, markerfacecolor='white', ms=20,
mew=3, markeredgecolor='#FC5200')
plt.fill_between(list(date_etime.keys()),
list(date_etime.values()), facecolor='#FC5200',alpha=0.1)
# Adding veritcal grids
plt.grid(axis="x")
# Hiding the y-ticks
ax.axes.get_yaxis().set_visible(False)
#Adding the title to the chart
plt.suptitle(list(date_etime.keys())[0]+" - "+
list(date_etime.keys())[-1],fontsize=24,x=0.195)
#Adding the subtitle to the chart
plt.title( "$\\bf{"+str(round(total_distance / 1609,1))+"}$mi | "+
"$\\bf{"+str(round(total_time/3600))+"}$h "+"$\\bf{"+
str(round(total_time%60))+"}$m | "+"$\\bf{"+
str(round(total_elevation))+"}$ft",fontsize=18,loc='left')
# Removing the spines on top, left and right
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
ax.spines['left'].set_visible(False)
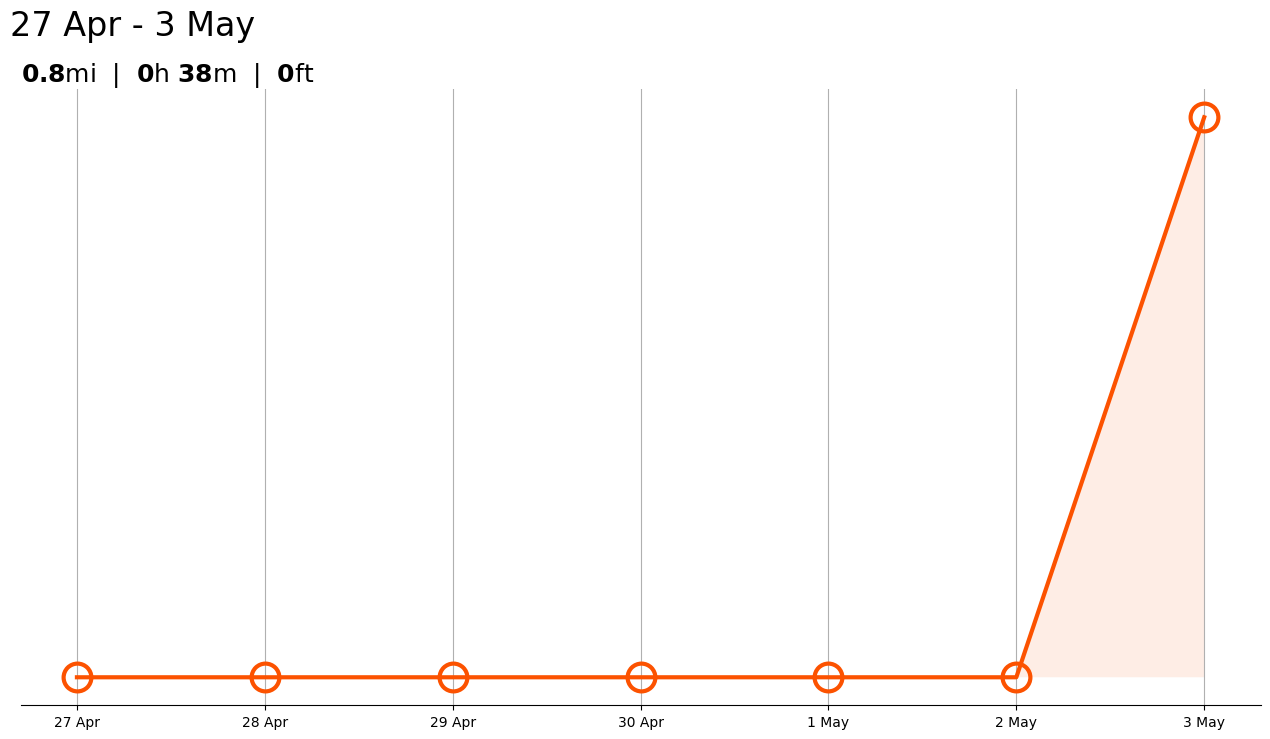
Above is a plot we created ourselves!
7.3 Visualizing Participant’s Runs!§
Strava’s website and app allows the user to visualize the routes for all their activities recorded synced on the Strava application. It is a very interesting feature as it lets the participants view the exact route they took during their activity on an actual map.
Let’s try to recreate the plots using the participant’s data! Here’s a reference to how our overall result will look like

Interestingly, Strava provides us with this route data in the form of polylines. In the df_strava dataframe we can see a column called summary_polyline for all the individual activities. We will be using this column for our plot!
Polyline is a encoded format that store coordinate location and it has to be decoded before it can be used. If we have a closer look into it, it is a bunch of characters that make no sense to an average reader.
[45]:
import polyline
import folium
#Dictionary to save the coordinates of the first ride
my_ride = map_summary_polyline_df.iloc[1].get(['map.summary_polyline']).apply(polyline.decode)['map.summary_polyline']
#Select one activity to find the centroid of the map.
centroid = [
np.mean([coord[0] for coord in my_ride]),
np.mean([coord[1] for coord in my_ride])
]
#Creating a map
m = folium.Map(location=centroid, zoom_start=13)
# Plot all rides on map
for i in range(len(map_summary_polyline_df.head())):
if len(map_summary_polyline_df.iloc[i].get(['map.summary_polyline'])['map.summary_polyline']) == 0:
continue
# Polyline.decode is a function that helps us decode this polyline data to coordinates
my_ride = map_summary_polyline_df.iloc[i].get(['map.summary_polyline']).apply(polyline.decode)['map.summary_polyline']
# We plot the route on the map.
folium.PolyLine(my_ride, color='red').add_to(m)
display(m)
8. Data Analysis§
Now that we have found, the weekly summary for the participant’s activity time, let’s plot some graphs to see if there is a correlation between the various metrics of the participants data.
In order to focus on the just the runs, we will have to clean the dataframe and only keep activities of the type ‘Run’.
[46]:
strava_df = max_speed_df.merge(max_heartrate_df.get(['start_date','max_heartrate']),on='start_date')
def filterRuns(data):
dataframe = []
for i in range(len(data)):
name = data.iloc[i].get('name')
if 'run' in name.lower():
dataframe.append(True)
else:
dataframe.append(False)
return dataframe
strava_df = strava_df[filterRuns(strava_df)]
strava_df
[46]:
| name | id | start_date | max_speed | max_heartrate | |
|---|---|---|---|---|---|
| 0 | Morning Run | 7795133796 | 2022-05-21T16:16:08Z | 3.7 | 177.0 |
| 1 | Afternoon Run | 7795133787 | 2022-05-20T21:52:46Z | 4.0 | 186.0 |
| 2 | Morning Run | 7170552790 | 2022-05-19T13:56:56Z | 4.2 | 159.0 |
| 3 | Morning Run | 7154793791 | 2022-05-14T17:31:06Z | 3.7 | 156.0 |
| 4 | Morning Run | 7127406894 | 2022-05-03T13:43:13Z | 3.5 | 174.0 |
| 6 | Lunch Run | 7056276906 | 2022-04-28T18:40:55Z | 3.7 | NaN |
[47]:
# We will drop the null values and only get the columns we need
df_runs_cleaned = strava_df.get(['max_speed','max_heartrate']).dropna()
As the strava api returns the max_speed values in meters/second and our above plots use miles, we will convert max speed to km/hour to maintain consistency.
[48]:
df_runs_cleaned = df_runs_cleaned.assign(max_speed =
df_runs_cleaned.get('max_speed').apply(lambda x: x*3.6))
Let’s plot the cleaned Data Frame below!
[49]:
df_runs_cleaned
[49]:
| max_speed | max_heartrate | |
|---|---|---|
| 0 | 13.32 | 177.0 |
| 1 | 14.40 | 186.0 |
| 2 | 15.12 | 159.0 |
| 3 | 13.32 | 156.0 |
| 4 | 12.60 | 174.0 |
Maybe the heart rate is correlated with how fast you run. Let’s test if this hypothesis is true. We will do so by plotting a scatterplot between those two metrics and finding the correlation.
First, we will plot a chart to see if there is a visual correlation between a partcipant’s max heart rate and their max speed.
[50]:
# Setting Figure Size in Seaborn
sns.set(rc={'figure.figsize':(16,8)})
# Setting Seaborn plot style
sns.set_style("darkgrid")
#Plotting our data
plot = sns.regplot(data=df_runs_cleaned, x="max_speed", y="max_heartrate")
#Renaming x and y labels
plot.set_ylabel("Maximum Heart Rate (bpm)", fontsize = 16)
plot.set_xlabel("Maximum Speed (km/hr)", fontsize = 16)
[50]:
Text(0.5, 0, 'Maximum Speed (km/hr)')
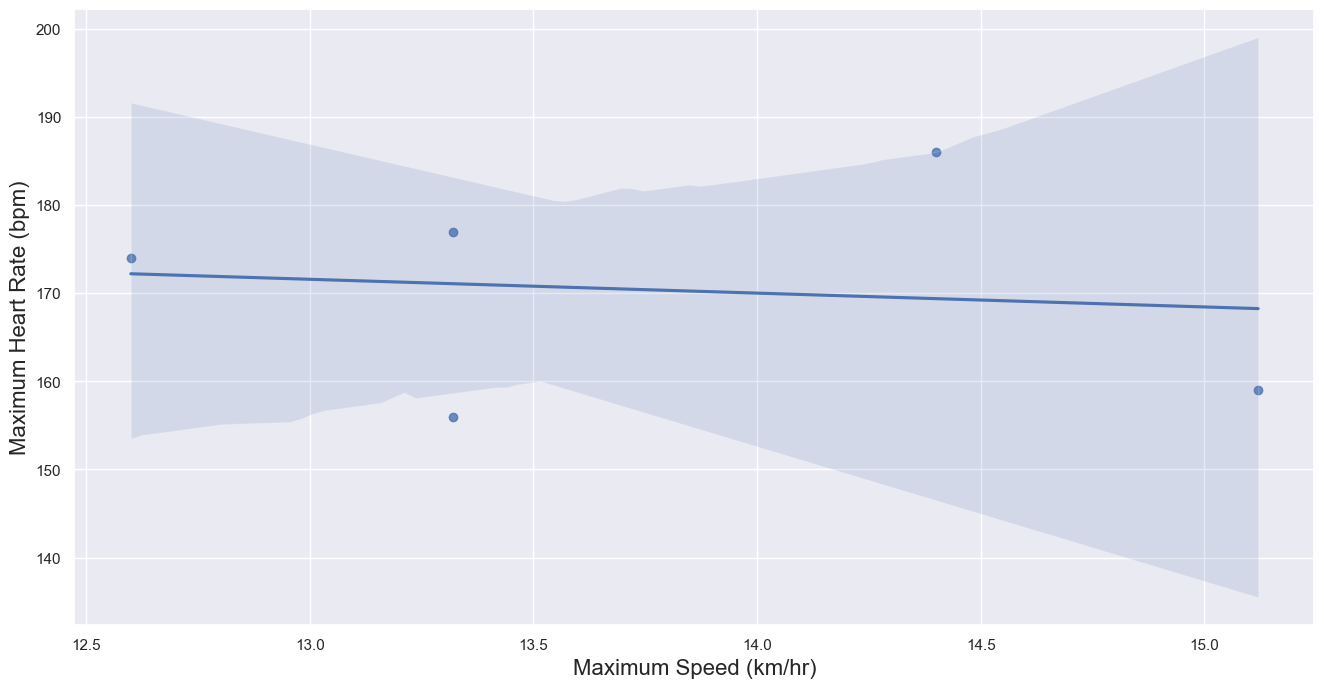
As we can see from the scatterplot above, our regression line hints that there might be a correlation between maximum speed and maximum heart rate. Let’s compute \(R^2\) just to see exactly how correlated.
We’ll follow this documentation and perform a linear regression to obtain the coefficient of determination.
[51]:
from scipy import stats
slope, intercept, r_value, p_value, std_err = stats.linregress(
df_runs_cleaned.get('max_speed'), df_runs_cleaned.get('max_heartrate'))
print(f'Slope: {slope:.3g}')
print(f'Coefficient of determination: {r_value**2:.3g}')
print(f'p-value: {p_value:.3g}')
Slope: -1.57
Coefficient of determination: 0.0154
p-value: 0.842
As we can see that the p-value is slightly over 30% which means that there is not enough evidence to convincingly conclude that that there is a correlation between heart rate and speed. Let’s try to locate the outliers in this data and find points that might be skewing our dataset and preventing us from gathering enough evidence to prove our correlation.
9.0 Outlier Detection§
Before finding the individual outlier values, it would be interesting to see the summary of our max_speed and max_heartrate parameters. It will give us a clear idea of what values are typical and which values can be considered atypical based on the data that we recieved from Strava.
[52]:
df_runs_cleaned_summary = df_runs_cleaned.describe().get(
['max_speed','max_heartrate'])
df_runs_cleaned_summary
[52]:
| max_speed | max_heartrate | |
|---|---|---|
| count | 5.000000 | 5.00000 |
| mean | 13.752000 | 170.40000 |
| std | 0.998959 | 12.62141 |
| min | 12.600000 | 156.00000 |
| 25% | 13.320000 | 159.00000 |
| 50% | 13.320000 | 174.00000 |
| 75% | 14.400000 | 177.00000 |
| max | 15.120000 | 186.00000 |
To locate the outliers we will be using a supervised as well as unsupervised algorithm called the Elliptic Envelope. In statistical studies, Elliptic Envelope created an imaginary elliptical area around a given dataset where values inside that imaginary area is considered to be normal data, and anything else is assumed to be outliers. It assumes that the given Data follows a gaussian distribution.
“The main idea is to define the shape of the data and anomalies are those observations that lie far outside the shape. First a robust estimate of covariance of data is fitted into an ellipse around the central mode. Then, the Mahalanobis distance that is obtained from this estimate is used to define the threshold for determining outliers or anomalies.” (S. Shriram and E. Sivasankar ,2019, pp. 221-225)
[53]:
from sklearn.covariance import EllipticEnvelope
#create the model, set the contamination as 0.02
EE_model = EllipticEnvelope(contamination = 0.02)
#implement the model on the data
outliers = EE_model.fit_predict(df_runs_cleaned[["max_speed", "max_heartrate"]])
#extract the labels
df_runs_cleaned["outlier"] = outliers
#change the labels
# We use -1 to mark an outlier and +1 for an inliner
df_runs_cleaned["outlier"] = df_runs_cleaned["outlier"].apply(
lambda x: str(-1) if x == -1 else str(1))
#extract the score
df_runs_cleaned["EE_scores"] = EE_model.score_samples(
df_runs_cleaned[["max_speed", "max_heartrate"]])
#print the value counts for inlier and outliers
print(df_runs_cleaned["outlier"].value_counts())
1 4
-1 1
Name: outlier, dtype: int64
/Users/saarth/opt/anaconda3/lib/python3.9/site-packages/sklearn/base.py:441: UserWarning: X does not have valid feature names, but EllipticEnvelope was fitted with feature names
warnings.warn(
/Users/saarth/opt/anaconda3/lib/python3.9/site-packages/sklearn/base.py:441: UserWarning: X does not have valid feature names, but EllipticEnvelope was fitted with feature names
warnings.warn(
Below we will replot the df_runs_cleaned dataframe to see how the two new columns were applied to it!
[54]:
df_runs_cleaned
[54]:
| max_speed | max_heartrate | outlier | EE_scores | |
|---|---|---|---|---|
| 0 | 13.32 | 177.0 | 1 | -0.236364 |
| 1 | 14.40 | 186.0 | 1 | -2.624880 |
| 2 | 15.12 | 159.0 | -1 | -15.545455 |
| 3 | 13.32 | 156.0 | 1 | -2.982775 |
| 4 | 12.60 | 174.0 | 1 | -2.155981 |
Now that we have labeled the outliers as -1, let’s try to see which values of max heartrate and max speed are being considered as outliers by our Elliptic Envelope Algorithm.
[55]:
outlier_df = df_runs_cleaned[df_runs_cleaned.get('outlier')=='-1'].get(
['max_heartrate','max_speed'])
outlier_df
[55]:
| max_heartrate | max_speed | |
|---|---|---|
| 2 | 159.0 | 15.12 |
Using the dataframe above, we can highlight these outlier values in our original scatterplot in order to visually asses which pair/s of max speed and max heart rate values are not following the general trend seen in our scatterplot.
[56]:
df_runs_cleaned.drop(outlier_df.index)
[56]:
| max_speed | max_heartrate | outlier | EE_scores | |
|---|---|---|---|---|
| 0 | 13.32 | 177.0 | 1 | -0.236364 |
| 1 | 14.40 | 186.0 | 1 | -2.624880 |
| 3 | 13.32 | 156.0 | 1 | -2.982775 |
| 4 | 12.60 | 174.0 | 1 | -2.155981 |
[57]:
# Setting Figure Size in Seaborn
sns.set(rc={'figure.figsize':(16,8)})
# Setting Seaborn plot style
sns.set_style("darkgrid")
# Plotting our data
# We will calculate the regression line while not accounting for our outliers
plot = sns.regplot(data=df_runs_cleaned.drop(outlier_df.index), x="max_speed",
y="max_heartrate")
#Renaming x and y labels
plot.set_ylabel("Maximum Heart Rate (bpm)", fontsize = 16)
plot.set_xlabel("Maximum Speed (km/hr)", fontsize = 16)
# Plotting the outlier and highlighting it
plt.scatter(outlier_df.get('max_speed'),outlier_df.get('max_heartrate'))
plt.scatter(outlier_df.get('max_speed'),outlier_df.get('max_heartrate'),
facecolors='red',alpha=.35, s=500)
[57]:
<matplotlib.collections.PathCollection at 0x7f851e001a90>
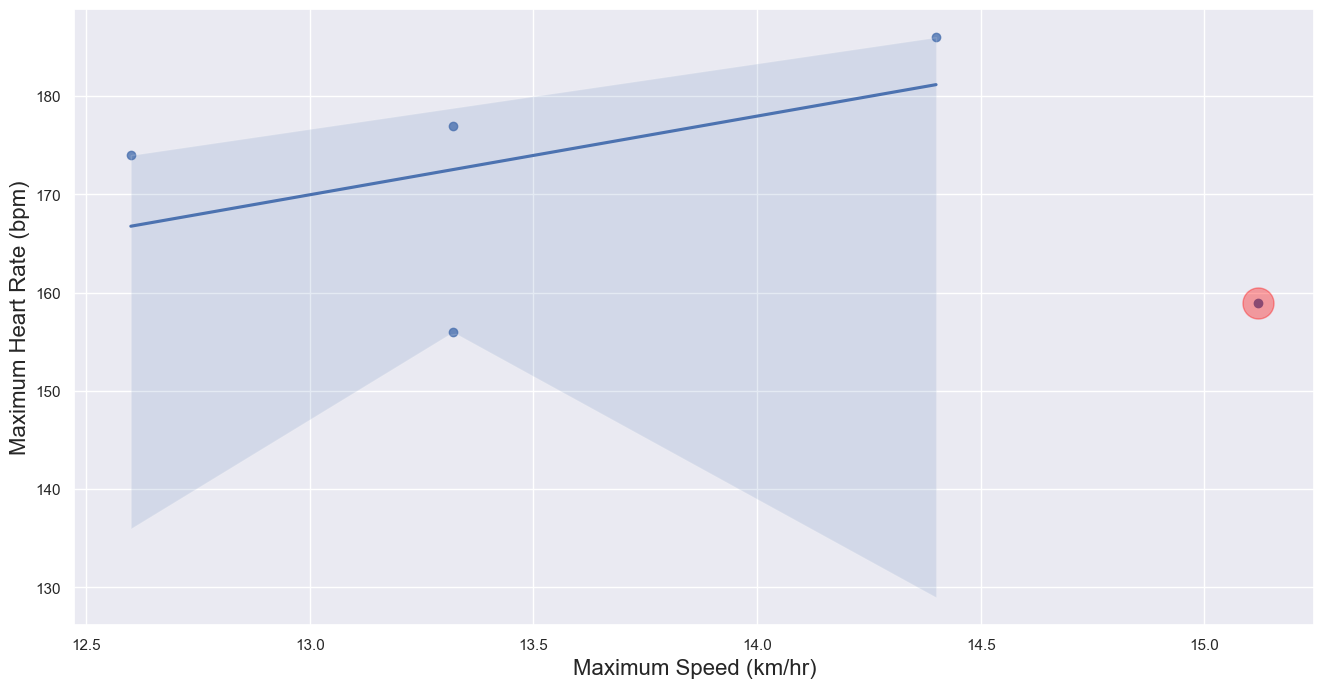
Thus, the points highlighted in red are ones that seem to not be following the general trend of our dataset. Lastly, let’s see what the new p-value is after outlier removal!
[58]:
slope, intercept, r_value, p_value, std_err = stats.linregress(
df_runs_cleaned.drop(outlier_df.index).get('max_speed'),
df_runs_cleaned.drop(outlier_df.index).get('max_heartrate'))
print(f'Slope: {slope:.3g}')
print(f'Coefficient of determination: {r_value**2:.3g}')
print(f'p-value: {p_value:.3g}')
Slope: 8.01
Coefficient of determination: 0.223
p-value: 0.528
Our new p-value after removing any outliers is 77.8% which is more than 30%. Therefore, after removing the outliers, our result is statistically less significant which means that there is not enough evidence to conclude that that there is a correlation between maximum speed and the maximum heart rate.